Table of Contents
- 5.1. Introduction
- 5.2. CDB
- 5.3. An example
- 5.4. Using keypaths
- 5.5. A session
- 5.6. CDB subscriptions
- 5.7. Reconnect
- 5.8. Loading initial data into CDB
- 5.9. Automatic schema upgrades and downgrades
- 5.10. Using initialization files for upgrade
- 5.11. Using MAAPI to modify CDB during upgrade
- 5.12. More complex schema upgrades
- 5.13. The full dhcpd example
This chapter describes how to use ConfD's built-in configuration database CDB. As a running example, we will describe a DHCP daemon configuration. CDB can also be used to store operational data - read more about this in Section 6.8, “Operational data in CDB”.
A network device needs to store its configuration somewhere. Usually the device configuration is stored in a database or in plain files, sometimes a combination of both.
ConfD has a built-in XML database which can be used to store the configuration data for the device. The database is called CDB - Configuration DataBase.
By default, ConfD stores all configuration data in CDB. The alternative is to use an external database as described in Chapter 7, The external database API. There are a number of advantages to CDB compared to using some external storage for configuration data. CDB has:
A solid model on how to handle configuration data in network devices, including a good update subscription mechanism.
A networked API whereby it is possible for an unconfigured device to find the configuration data on the network and use that configuration.
Fast lightweight database access. CDB by default keeps the entire configuration in RAM as well as on disk.
Ease of use. CDB is already integrated into ConfD, the database is lightweight and has no maintenance needs. Writing instrumentation functions to access data is easy.
Automatic support for upgrade and downgrade of configuration data. This is a key feature, which is useful not only when performing actual up/downgrades on the device. It also greatly simplifies the development process by allowing individual developers to add/delete items in the configuration without any impact whatsoever on other developers. This will be fully described later.
When using CDB to store the configuration data, the applications need to be able to:
Read configuration data from the database.
React when the database is written to. There are several possible writers to the database, such as the CLI, NETCONF sessions, the Web UI, or the NETCONF agent. Suppose an operator runs the CLI and changes the value of some leaf. When this happens, the application needs to be informed about the configuration change.
The following figure illustrates the architecture when CDB is used.
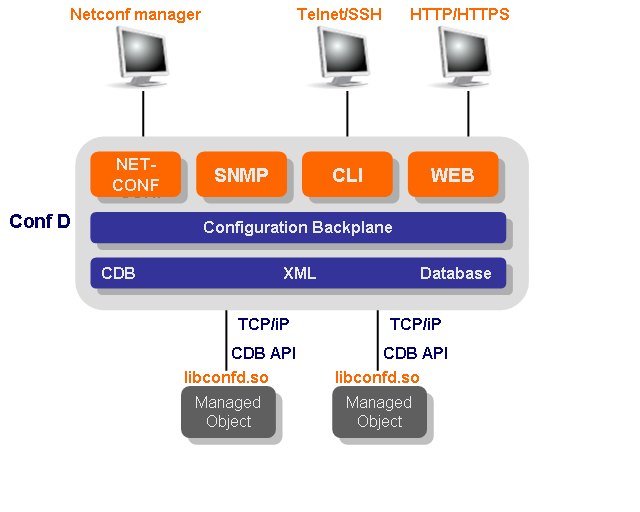 |
ConfD CDB architecture scenario
The Applications/Managed Objects in the figure above read
configuration data and subscribe to changes to the database using
a simple RPC-based API. The API is part of the
libconfd.so shared library and is fully
documented in the UNIX man page confd_lib_cdb(3). Since the API is RPC-based,
the Applications may run on other hosts that are not running ConfD
- which could be used for example in a chassis-based system where
ConfD only would run on the management blade, and the managed
applications on other blades in the system.
Let us look at a simple example which will illustrate how to populate the database, how to read from it using the C API, as well as react to changes to the data. First we need a YANG module (see Chapter 3, The YANG Data Modeling Language for more details about how to write data models in YANG). Consider this simplified, but functional, example:
Example 5.1. a simple server data model,
servers.yang
module servers {
namespace "http://example.com/ns/servers";
prefix servers;
import ietf-inet-types {
prefix inet;
}
revision "2006-09-01" {
description "Initial servers data model";
}
/* A set of server structures */
container servers {
list server {
key name;
max-elements 64;
leaf name {
type string;
}
leaf ip {
type inet:ip-address;
mandatory true;
}
leaf port {
type inet:port-number;
mandatory true;
}
}
}
}
Since we are using CDB here, ConfD will keep an XML tree conforming to the above data model in its internal persistent XML database.
We start by saving the YANG module to a file,
servers.yang and compile and link the data
model into a single servers.fxs which is the
binary format, used by ConfD, of a YANG module.
$ confdc -c servers.yang
We then proceed to use the --emit-h flag to
generate a .h file which contains the namespace symbol
(servers__ns) which we need in order to use
the CDB API.
$ confdc --emit-h servers.h servers.fxs $ head servers.h #ifndef _SERVERS_H_ #define _SERVERS_H_ #ifndef servers__ns #define servers__ns 686487091 #define servers__ns_id "http://example.com/ns/servers" #define servers__ns_uri "http://example.com/ns/servers" #endif
Once we have compiled the YANG module, we can start ConfD. We need to provide a configuration file to ConfD which indicates that we want ConfD to store the configuration.
The relevant parts from the
confd.conf configuration file are:
<loadPath>
<dir>/etc/confd</dir>
</loadPath>
...
<cdb>
<enabled>true</enabled>
<dbDir>/var/confd/cdb</dbDir>
</cdb>The newly generated .fxs file must be copied to the
directory /etc/confd and the directory
/var/confd/cdb must exist and be writable.
Thus:
$ cp servers.fxs /etc/confd $ mkdir /var/confd/cdb $ confd -v --foreground
By far the easiest way to populate the database with some actual data is to run the CLI.
$ confd_cli -u admin
admin connected from 127.0.0.1 using console on buzz
admin@buzz> configure private
Entering configuration mode "private"
admin@buzz% set servers server www
admin@buzz% set servers server www port 80
admin@buzz% set servers server www ip 192.168.128.1
admin@buzz% commit
Configuration committed
admin@buzz> show configuration
servers {
server www {
ip 192.168.128.1;
port 80;
}
}Now the database is populated with a single server instance.
What remains to conclude our simple example is to write our
application - our managed object - the code that uses the
configuration data in the database. The implied meaning of the
servers.yang YANG module is that the managed
object would start and stop the services in the configuration. We
will not do that; we will merely show how to read the
configuration from the CDB database and react to changes in
CDB.
The code is straightforward. We are using the API functions
from libconfd.so. The CDB API is fully
described in the UNIX man page confd_lib_cdb(3).
Main looks like this:
int main(int argc, char **argv)
{
struct sockaddr_in addr;
int subsock;
int status;
int spoint;
addr.sin_addr.s_addr = inet_addr("127.0.0.1");
addr.sin_family = AF_INET;
addr.sin_port = htons(CONFD_PORT);
confd_init(argv[0], stderr, CONFD_SILENT);
if ((subsock = socket(PF_INET, SOCK_STREAM, 0)) < 0 )
confd_fatal("Failed to open socket\n");
if (cdb_connect(subsock, CDB_SUBSCRIPTION_SOCKET,
(struct sockaddr*)&addr,
sizeof (struct sockaddr_in)) < 0)
confd_fatal("Failed to confd_connect() to confd \n");
if ((status =
cdb_subscribe(subsock, 3, servers__ns, &spoint,"/servers"))
!= CONFD_OK) {
fprintf(stderr, "Terminate: subscribe %d\n", status);
exit(1);
}
if (cdb_subscribe_done(subsock) != CONFD_OK)
confd_fatal("cdb_subscribe_done() failed");
if ((status = read_conf(&addr)) != CONFD_OK) {
fprintf(stderr, "Terminate: read_conf %d\n", status);
exit(1);
}
/* ... */
The code initializes the library, reads the configuration
and creates a socket to CDB. One socket is a read socket and it
is used to read configuration data by means of CDB API read
functions, while the other is a subscription socket. The
subscription socket must be part of the client
poll() set. Whenever data arrives on the
subscription socket, the client invokes a CDB API function,
cdb_read_subscription_socket() on the
subscription socket. The subscription model will be explained
further later in this chapter.
The read_conf() function reads the
configuration data from CDB and stores it in local ephemeral
(temporary) data structures. We have:
#include "servers.h"
struct server {
char name[BUFSIZ];
struct in_addr ip;
unsigned int port;
};
static struct server running_db[64];
static int num_servers = 0;
static int read_conf(struct sockaddr_in *addr)
{
int rsock, i, n, st = CONFD_OK;
struct in_addr ip;
u_int16_t port;
char buf[BUFSIZ];
if ((rsock = socket(PF_INET, SOCK_STREAM, 0)) < 0 )
return CONFD_ERR;
if (cdb_connect(rsock, CDB_READ_SOCKET, (struct sockaddr*)addr,
sizeof (struct sockaddr_in)) < 0)
return CONFD_ERR;
if (cdb_start_session(rsock, CDB_RUNNING) != CONFD_OK)
return CONFD_ERR;
cdb_set_namespace(rsock, servers__ns);
num_servers = 0;
if ((n = cdb_num_instances(rsock, "/servers/server")) < 0) {
cdb_close(rsock);
return n;
}
num_servers = n;
for(i=0; i<n; i++) {
if ((st = cdb_get_str(rsock, buf, BUFSIZ,
"/servers/server[%d]/name",i)) != CONFD_OK)
break;
if ((st = cdb_get_ipv4(
rsock, &ip,"/servers/server[%d]/ip",i))!= CONFD_OK)
break;
if ((st = cdb_get_u_int16(
rsock, &port, "/servers/server[%d]/port",i)) != CONFD_OK)
break;
strcpy(running_db[i].name, buf);
running_db[i].ip.s_addr = ip.s_addr;
running_db[i].port = port;
}
cdb_close(rsock);
return st;
}
The code first creates a read socket to ConfD by means of
cdb_connect(). Following that, the code
figures out how many server instances CDB has stored
and then loops over all of those instances and reads the
individual leaves with the different cdb_get_
functions.
Finally we have our poll() loop. The
subscription socket we created in main() must
be added to the poll set - and whenever that file descriptor has
IO ready to read we must act. When subsock is
ready to read, the following code fragment should be
executed:
int sub_points[1];
int reslen;
if ((status = cdb_read_subscription_socket(subsock,
sub_points,
&reslen)) != CONFD_OK)
exit(status);
if (reslen > 0) {
if ((status = read_conf(&addr)) != CONFD_OK)
exit(1);
}
print_servers(); /* do something with data here... */
if ((status =
cdb_sync_subscription_socket(subsock, CDB_DONE_PRIORITY))
!= CONFD_OK) {
exit(status);
}
Instead of actually using the data we will merely print it to stdout when we receive any changes:
static void print_servers()
{
int i;
for (i=0; i < num_servers; i++) {
printf("server %d: %s %s:%d\n", i, running_db[i].name,
inet_ntoa(running_db[i].ip), running_db[i].port);
}
}
We'll go through all the CDB API functions used in the C
code, but first a note on the path notation. Several of the API
functions take a keypath as a parameter. A keypath leads down into
the configuration data tree. A keypath can be either absolute or
relative. An absolute keypath starts from the root of the tree,
while a relative path starts from the "current position" in the
tree. They are differentiated by presence or absence of a leading
"/". It is possible to change the "current position" with for
example the cdb_cd() function.
XML elements that are containers for other XML elements,
such as the servers container that contains multiple
server instances, can be traversed using two different
path notations. In our code above, we use the function
cdb_num_instances() to figure out how many
children a list has, and then traverse all children using a
[%d] notation. The children of a list have an
implicit numbering starting at 0. Thus the path:
/servers/server[2]/port refers to the "port" leaf of
the third server in the configuration. This numbering
is only valid during the current CDB session. CDB is always
locked for the duration of the read session.
We can also refer to list instances using the values of the
keys of the list. Remember that we specified in the data model
which leaf(s) in the XML structure were keys using the key
name statement at the beginning of the list. In our case a
server has the name leaf as key. So the
path: /servers/server{www}/ip refers to the
ip leaf of the server whose name is "www".
A YANG list may have more than one key. In the next section
we will provide an example where we configure a DHCP daemon. That
data model uses multiple keys and for example the path:
/dhcp/subNets/subNet{192.168.128.0
255.255.255.0}/routers refers to the routers list of the
subNet which has key "192.168.128.0
255.255.255.0".
The syntax for keys is a space separated list of key values
enclosed within curly brackets: { Key1 Key2
...}
Which version of bracket notation to use depends on the
situation. For example the bracket notation is normally used when
looping through all instances. As a convenience all functions
expecting keypaths accept formatting characters and accompanying
data items. For example cdb_get("server[%d]/ifc{%s}/mtu", 2,
"eth0") to fetch the MTU of the third server instance's
interface named "eth0". Using relative paths and
cdb_pushd() it is possible to write code that
can be re-used for common sub-trees. An example of this is
presented further down.
The current position also includes the namespace. To read
elements from a different namespace use the
cdb_set_namespace() function.
It is important to consider that CDB is locked for writing
during a read session using the C API. A session starts with
cdb_start_session() and the lock is not
released until the cdb_end_session() (or the
cdb_close()) call. CDB will also
automatically release the lock if the socket is closed for some
other reason, such as program termination.
In the example above we created a new socket each time we
called read_conf(). It is also possible to
re-use an existing connection.
Example 5.2. Pseudo code showing several sessions reusing one connection
cdb_connect(s); .. cdb_start_session(s); /* Start session and take CDB lock */ cdb_cd(); cdb_get(); cdb_end_session(s); /* lock is released */ .. cdb_start_session(s); /* Start session and take CDB lock */ cdb_get(); cdb_end_session(s); /* lock is released */ .. cdb_close(s);
The CDB subscription mechanism allows an external program to be notified when different parts of the configuration changes. At the time of notification it is also possible to iterate through the changes written to CDB. Subscriptions are always towards the running datastore (it is not possible to subscribe to changes to the startup datastore). Subscriptions towards the operational data kept in CDB are also possible, but the mechanism is slightly different, see below.
The first thing to do is to inform CDB which paths we want
to subscribe to, registering a path returns a subscription point
identifier. This is done with the
cdb_subscribe() function. Each subscriber can
have multiple subscription points, and there can be many different
subscribers. Every point is defined through a path - similar to
the paths we use for read operations, with the exception that
instead of fully instantiated paths to list instances we can
selectively use tagpaths.
We can subscribe either to specific leaves, or entire subtrees. Explaining this by example we get:
/named/options/pid-filea subscription to a leaf. Only changes to this leaf will generate a notification.
/serversMeans that we subscribe to any changes in the subtree rooted at
/servers. This includes additions or removals ofserverinstances, as well as changes to already existingserverinstances./servers/server{www}/ipMeans that we only want to be notified when the server "www" changes its ip address.
/servers/server/ipMeans we want to be notified when the leaf
ipis changed in any server instance.
When adding a subscription point the client must also
provide a priority, which is an integer. As CDB is changed, the
change is part of a transaction. For example the transaction is
initiated by a commit operation from the CLI or
a candidate-commit operation in NETCONF
resulting in the running database being modified. As the last part
of the transaction CDB will generate notifications in lock-step
priority order. First all subscribers at the lowest numbered
priority are handled, once they all have replied and synchronized
by calling cdb_sync_subscription_socket() the
next set - at the next priority level - is handled by CDB. Not
until all subscription points have been acknowledged is the
transaction complete. This implies that if the initiator of the
transaction was for example a commit command in
the CLI, the command will hang until notifications have been
acknowledged.
Note that even though the notifications are delivered within the transaction it is not possible for a subscriber to reject the changes (since this would break the two-phase commit protocol used by the ConfD backplane towards all data-providers).
When a client is done subscribing it needs to inform ConfD
it is ready to receive notifications. This is done by first
calling cdb_subscribe_done(), after which the
subscription socket is ready to be polled.
As a subscriber has read its subscription notifications
using cdb_read_subscription_socket() it can
iterate through the changes that caused the particular
subscription notification using the
cdb_diff_iterate() function. It is also
possible to start a new read-session to the CDB_PRE_COMMIT_RUNNING
database to read the running database as it was before the pending
transaction.
Subscriptions towards the operational data in CDB are similar to the above, but due to the fact that the operational data store is designed for light-weight access, and thus does not have transactions and normally avoids the use of any locks, there are several differences - in particular:
Subscription notifications are only generated if the writer obtains a "subscription lock", by using the
cdb_start_session2()function with the CDB_LOCK_REQUEST flag, see the confd_lib_cdb(3) manual page. It is possible to obtain a "subscription lock" for a subtree of the operational data store by using the CDB_LOCK_PARTIAL flag.Subscriptions are registered by using the
cdb_subscribe2()function with typeCDB_SUB_OPERATIONAL(orcdb_oper_subscribe()) rather thancdb_subscribe().No priorities are used.
Neither the writer that generated the subscription notifications nor other writes to the same data are blocked while notifications are being delivered. However the subscription lock remains in effect until notification delivery is complete.
The previous value for a modified leaf is not available when using the
cdb_diff_iterate()function.
Essentially a write operation towards the operational data
store, combined with the subscription lock, takes on the role of a
transaction for configuration data as far as subscription
notifications are concerned. This means that if operational data
updates are done with many single-element write operations, this
can potentially result in a lot of subscription notifications.
Thus it is a good idea to use the multi-element
cdb_set_object() etc functions for updating
operational data that applications subscribe to.
Since write operations that do not attempt to obtain a subscription lock are allowed to proceed even during notification delivery, it is the responsibility of the applications using the operational data store to obtain the lock as needed when writing. E.g. if subscribers should be able to reliably read the exact data that resulted from the write that triggered their subscription, a subscription lock must always be obtained when writing that particular set of data elements. One possibility is of course to obtain a lock for all writes to operational data, but this may have an unacceptable performance impact.
To view registered subscribers use the confd --status command. For details on how to use the different subscription functions see the confd_lib_cdb(3) manual page.
If ConfD is restarted, our CDB sockets obviously die. The correct thing to do then is to re-open the cdb sockets and re-read the configuration. In the case of a high availability setup this also applies. If we are connected to one ConfD node and that node dies, we must reconnect to another ConfD node and read/subscribe to the configuration from that node.
If the configuration has not changed we do not want to
restart our managed objects, we just want to reconnect our CDB
sockets. The API function cdb_get_txid() will
read the last transaction id from our cdb socket. The id is
guaranteed to be unique. We issue the call
cdb_get_txid() on the data socket and we must
not have an active read session on that socket while issuing the
call.
Example 5.3. Pseudo code demonstrating how to avoid re-reading the configuration
struct cdb_txid prev_stamp;
cdb_connect(s);
load_config(s);
cdb_get_txid(s, &prev_stamp);
...
subscribe(....);
while (1) {
poll(...);
if (has_new_data(s)) {
load_config(s);
cdb_get_txid(s, &prev_stamp);
}
else if (is_closed(s)) {
struct cdb_txid new_stamp;
cdb_connect(s);
cdb_get_txid(s, &new_stamp);
if ((prev_stamp.s1 == new_stamp.s1) &&
(prev_stamp.s2 == new_stamp.s2) &&
(prev_stamp.s3 == new_stamp.s3) &&
(strcmp(prev_stamp.master, new_stamp.master) == 0)) {
/* no need to re-read config, it hasn't changed */
continue;
}
else {
load_config(s);
cdb_get_txid(s, &prev_stamp);
}
}
}When ConfD starts for the first time, assuming CDB is enabled, the CDB database is empty. CDB is configured to store its data in a directory as in:
<cdb>
<enabled>true</enabled>
<dbDir>/var/confd/cdb</dbDir>
</cdb>At startup, when CDB is empty, i.e. no database files are found in the CDB directory, CDB will try to initialize the database from all instantiated XML documents found in the CDB directory. This is the mechanism we use to have an empty database initialized to some default setup.
This feature can be used to for example reset the configuration back to some factory setting or some such.
For example, assume we have the data model from Example 5.1, “a simple server data model,
servers.yang”. Furthermore, assume CDB is
empty, i.e. no database files at all reside under
/var/confd/cdb. However we do have a file,
/var/confd/cdb/foobar.xml containing the
following data:
<servers:servers xmlns:servers="http://example.com/ns/servers">
<servers:server>
<servers:name>www</servers:name>
<servers:ip>192.168.3.4</servers:ip>
<servers:port>88</servers:port>
</servers:server>
<servers:server>
<servers:name>www2</servers:name>
<servers:ip>192.168.3.5</servers:ip>
<servers:port>80</servers:port>
</servers:server>
<servers:server>
<servers:name>smtp</servers:name>
<servers:ip>192.168.3.4</servers:ip>
<servers:port>25</servers:port>
</servers:server>
<servers:server>
<servers:name>dns</servers:name>
<servers:ip>192.168.3.5</servers:ip>
<servers:port>53</servers:port>
</servers:server>
</servers:servers>
CDB will be initialized from the above XML document. The feature of initializing CDB with some predefined set of XML elements is used to initialize the AAA database. This is described in Chapter 14, The AAA infrastructure.
All files ending in .xml will be loaded
(in an undefined order) and committed in a single transaction when
CDB enters start phase 1 (see Section 28.5, “Starting ConfD” for more details on
start phases). The format of the init files is rather lax in that
it is not required that a complete instance document following the
data-model is present, much like the NETCONF
edit-config operation. It is also possible to wrap
multiple top-level tags in the file with a surrounding config tag,
like this:
<config xmlns="http://tail-f.com/ns/config/1.0"> ... </config>
Software upgrades and downgrades represent one of the main problems of managing configuration data of network devices. Each software release for a network device is typically associated with a certain version of configuration data layout, i.e. a schema. In ConfD the schema is the data model stored in the .fxs files. Once CDB has initialized it also stores a copy of the schema associated with the data it holds.
Every time ConfD starts, CDB will check the current contents of the .fxs files with its own copy of the schema files. If CDB detects any changes in the schema it initiates an upgrade transaction. In the simplest case CDB automatically resolves the changes and commits the new data before ConfD reaches start-phase one.
An example of how the CDB automatically handles upgrades follows. For version 1.0 of the "forest configurator" software project the following YANG module is used:
Example 5.4. Version 1.0 of the forest module
module forest {
namespace "http://example.com/ns/forest";
prefix forest;
revision "2006-09-01" {
description "Initial forest model";
}
container forest {
list tree {
key name;
min-elements 2;
max-elements 1024;
leaf name {
type string;
}
leaf height {
type uint8;
mandatory true;
}
leaf type {
type string;
mandatory true;
}
}
list flower {
key name;
max-elements 1024;
leaf name {
type string;
}
leaf type {
type string;
mandatory true;
}
leaf color {
type string;
mandatory true;
}
}
}
}
The YANG module will be mounted at / in the larger compounded data model tree. We start ConfD and populate the CDB, e.g. by using the ConfD CLI. The programmer then writes C code which reads these items from the configuration database.
To demonstrate the automatic upgrade, we will assume that CDB is populated with the instance data in Example 5.5, “Initial forest instance document”
Example 5.5. Initial forest instance document
<forest xmlns="http://example.com/ns/forest">
<tree>
<name>George</name><height>10</height><type>oak</type>
</tree>
<tree>
<name>Eliza</name><height>15</height><type>oak</type>
</tree>
<tree>
<name>Henry</name><height>12</height><type>pine</type>
</tree>
<flower>
<name>Sebastian</name><type>dandelion</type><color>yellow</color>
</flower>
<flower>
<name>Alvin</name><type>tulip</type><color>white</color>
</flower>
</forest>
During the development of the next version of the "forest
configurator" software project a couple of changes were made to
the configuration data schema. The tree list height was
found to need more than 256 possible values and expanded to a
32-bit integer, and two new leaves color and
birthday were added. The list flower had an
optional edible leaf added, and the color
changed type to a more strict enumeration type. The result is in
Example 5.6, “Version 2.0 of the forest module”.
Example 5.6. Version 2.0 of the forest module
module forest {
namespace "http://example.com/ns/forest";
prefix forest;
import tailf-xsd-types {
prefix xs;
}
revision "2009-10-01" {
description
"Needed room for taller trees.
Flowers can be edible.";
}
revision "2008-09-01" {
description "Initial forest model";
}
typedef colorType {
type enumeration {
enum unknown;
enum blue;
enum yellow;
enum red;
enum green;
}
}
container forest {
list tree {
key name;
min-elements 2;
max-elements 1024;
leaf name {
type string;
}
leaf height {
type int32;
mandatory true;
}
leaf birthday {
type xs:date;
default 2006-09-01;
}
leaf color {
type colorType;
default unknown;
}
leaf type {
type string;
mandatory true;
}
}
list flower {
key name;
max-elements 1024;
leaf name {
type string;
}
leaf type {
type string;
mandatory true;
}
leaf edible {
type empty;
}
leaf color {
type colorType;
default unknown;
}
}
}
}
After compiling this new version of the YANG module into an
fxs file using confdc and restarting ConfD with
the new schema, CDB automatically detects that the namespace http://example.com/ns/forest has been
modified. CDB will then update the schema and
the contents of the database. When ConfD has started the data in
the database now looks like in Example 5.7, “Forest instance document after upgrade”
Example 5.7. Forest instance document after upgrade
<forest xmlns="http://example.com/ns/forest">
<tree>
<name>Eliza</name>
<height>15</height>
<birthday>2006-09-01</birthday>
<color>unknown</color>
<type>oak</type>
</tree>
<tree>
<name>George</name>
<height>10</height>
<birthday>2006-09-01</birthday>
<color>unknown</color>
<type>oak</type>
</tree>
<tree>
<name>Henry</name>
<height>12</height>
<birthday>2006-09-01</birthday>
<color>unknown</color>
<type>pine</type>
</tree>
<flower>
<name>Alvin</name>
<type>tulip</type>
<color>unknown</color>
</flower>
<flower>
<name>Sebastian</name>
<type>dandelion</type>
<color>yellow</color>
</flower>
</forest>
Let's follow what CDB does by checking the devel log. The
devel log is meant to be used as support while the application is
developed. It is enabled in confd.conf as
shown in Example 5.8, “Enabling the developer log”.
Example 5.8. Enabling the developer log
<developerLog>
<enabled>true</enabled>
<file>
<enabled>true</enabled>
<name>/var/confd/log/devel.log</name>
</file>
</developerLog>
<developerLogLevel>trace</developerLogLevel>Example 5.9. Developer log entries resulting from upgrade
upgrade: http://example.com/ns/forest -> http://example.com/ns/forest
upgrade: /forest/flower/{"Alvin"}/color: -> unknown (default because old value white does not fit in new type)
upgrade: /forest/flower/{"Sebastian"}/color: -> yellow (but with new type)
upgrade: /forest/tree/{"Eliza"}/birthday: added, with default (2006-09-01)
upgrade: /forest/tree/{"Eliza"}/color: added, with default (unknown)
upgrade: /forest/tree/{"Eliza"}/height: -> 15 (but with new type)
upgrade: /forest/tree/{"George"}/birthday: added, with default (2006-09-01)
upgrade: /forest/tree/{"George"}/color: added, with default (unknown)
upgrade: /forest/tree/{"George"}/height: -> 10 (but with new type)
upgrade: /forest/tree/{"Henry"}/birthday: added, with default (2006-09-01)
upgrade: /forest/tree/{"Henry"}/color: added, with default (unknown)
upgrade: /forest/tree/{"Henry"}/height: -> 12 (but with new type)
CDB can automatically handle the following changes to the schema:
- Deleted elements
When an element is deleted from the schema, CDB simply deletes it (and any children) from the database.
- Added elements
If a new element is added to the schema it needs to either be optional, dynamic, or have a default value. New elements with a default are added set to their default value. New dynamic or optional elements are simply noted as a schema change.
- Re-ordering elements
An element with the same name, but in a different position on the same level, is considered to be the same element. If its type hasn't changed it will retain its value, but if the type has changed it will be upgraded as described below.
- Type changes
If a leaf is still present but its type has changed, automatic coercions are performed, so for example integers may be transformed to their string representation if the type changed from e.g. int32 to string. Automatic type conversion succeeds as long as the string representation of the current value can be parsed into its new type. (Which of course also implies that a change from a smaller integer type, e.g. int8, to a larger type, e.g. int32, succeeds for any value - while the opposite will not hold, but might!)
If the coercion fails, any supplied default value will be used. If no default value is present in the new schema the automatic upgrade will fail.
Type changes when user-defined types are used are also handled automatically, provided that some straightforward rules are followed for the type definitions. Read more about user-defined types in the confd_types(3) manual page, which also describes these rules.
- Hash changes
When a hash value of particular element has changed (due to an addition of, or a change to, a
tailf:id-valuestatement) CDB will update that element.- Key changes
When a key of a list is modified, CDB tries to upgrade the key using the same rules as explained above for adding, deleting, re-ordering, change of type, and change of hash value. If automatic upgrade of a key fails the entire list instance will be deleted.
- Default values
If a leaf has a default value, which has not been changed from its default, then the automatic upgrade will use the new default value (if any). If the leaf value has been changed from the old default, then that value will be kept.
- Adding / Removing namespaces
If a namespace no longer is present after an upgrade, CDB removes all data in that namespace. When CDB detects a new namespace, it is initialized with default values.
- Changing to/from operational
Elements that previously had
config falseset that are changed into database elements will be treated as a added elements. In the opposite case, where data elements in the new data model are tagged withconfig false, the elements will be deleted from the database.- Callpoint changes
CDB only considers the part of the data model in YANG modules that do not have external callpoints (see Chapter 7, The external database API). But while upgrading, CDB does handle moving subtrees into CDB from a callpoint and vice versa. CDB simply considers these as added and deleted schema elements.
Thus an application can be developed using CDB in the first development cycle. When the external database component is ready it can easily replace CDB without changing the schema.
Should the automatic upgrade fail, exit codes and log-entries will indicate the reason (see Section 28.11, “Disaster management”).
As described earlier, when ConfD starts with an empty CDB
database, CDB will load all instantiated XML documents found in
the CDB directory and use these to initialize the the database.
We can also use this mechanism for CDB upgrade, since CDB will
again look for files in the CDB directory ending in
.xml when doing an upgrade.
This allows for handling many of the cases that the automatic upgrade can not do by itself, e.g. addition of mandatory leaves (without default statements), or multiple instances of new dynamic containers. Most of the time we can probably simply use the XML init file that is appropriate for a fresh install of the new version also for the upgrade from a previous version.
When using XML files for initialization of CDB, the complete contents of the files is used. On upgrade however, doing this could lead to modification of the user's existing configuration - e.g. we could end up resetting data that the user has modified since CDB was first initialized. For this reason two restrictions are applied when loading the XML files on upgrade:
Only data for elements that are new as of the upgrade (i.e. elements that did not exist in the previous schema) will be considered.
The data will only be loaded if all old (i.e. previously existing) optional/dynamic parent elements and instances exist in the current configuration.
To clarify this, we will look again at Example 5.1, “a simple server data model,
servers.yang”. In version 1.5 of the server
manager, it was realized that the data model had a serious
shortcoming: There was no way to specify the protocol to use, TCP
or UDP. To fix this, another leaf was added to the
/servers/server list, and the new YANG module looks
like this:
Example 5.10. Version 1.5 of the servers.yang module
module servers {
namespace "http://example.com/ns/servers";
prefix servers;
import ietf-inet-types {
prefix inet;
}
revision "2007-06-01" {
description "added protocol.";
}
revision "2006-09-01" {
description "Initial servers data model";
}
/* A set of server structures */
container servers {
list server {
key name;
max-elements 64;
leaf name {
type string;
}
leaf ip {
type inet:ip-address;
mandatory true;
}
leaf port {
type inet:port-number;
mandatory true;
}
leaf protocol {
type enumeration {
enum tcp;
enum udp;
}
mandatory true;
}
}
}
}
Since it was considered important that the user explicitly specified the protocol, the new leaf was made mandatory. Of course the XML init file was updated to include this leaf, and now looks like this:
<servers:servers xmlns:servers="http://example.com/ns/servers">
<servers:server>
<servers:name>www</servers:name>
<servers:ip>192.168.3.4</servers:ip>
<servers:port>88</servers:port>
<servers:protocol>tcp</servers:protocol>
</servers:server>
<servers:server>
<servers:name>www2</servers:name>
<servers:ip>192.168.3.5</servers:ip>
<servers:port>80</servers:port>
<servers:protocol>tcp</servers:protocol>
</servers:server>
<servers:server>
<servers:name>smtp</servers:name>
<servers:ip>192.168.3.4</servers:ip>
<servers:port>25</servers:port>
<servers:protocol>tcp</servers:protocol>
</servers:server>
<servers:server>
<servers:name>dns</servers:name>
<servers:ip>192.168.3.5</servers:ip>
<servers:port>53</servers:port>
<servers:protocol>udp</servers:protocol>
</servers:server>
</servers:servers>
We can then just use this new init file for the upgrade, and
the existing server instances in the user's configuration will get
the new /servers/server/protocol leaf filled in as
expected. However some users may have deleted some of the original
servers from their configuration, and in those cases we obviously
do not want those servers to get re-created during the upgrade
just because they are present in the XML file - the above
restrictions make sure that this does not happen. Here is what the
configuration looks like after upgrade if the "smtp" server has
been deleted before upgrade:
<servers xmlns="http://example.com/ns/servers">
<server>
<name>dns</name>
<ip>192.168.3.5</ip>
<port>53</port>
<protocol>udp</protocol>
</server>
<server>
<name>www</name>
<ip>192.168.3.4</ip>
<port>88</port>
<protocol>tcp</protocol>
</server>
<server>
<name>www2</name>
<ip>192.168.3.5</ip>
<port>80</port>
<protocol>tcp</protocol>
</server>
</servers>
This example also implicitly shows a limitation with this method: If the user has created additional servers, the new XML file will not specify what protocol to use for those servers, and the upgrade cannot succeed unless the external program method is used, see below. However the example is a bit contrived - in practice this limitation is rarely a problem: It does not occur for new lists or optional elements, nor for new mandatory elements that are not children of old lists. And in fact correctly adding this "protocol" leaf for user-created servers would require user input - it can not be done by any fully automated procedure.
Note
Since CDB will attempt to load all
*.xml files in the CDB directory at the
time of upgrade, it is important to not leave XML init files
from a previous version that are no longer valid there.
It is always possible to write an external program to change the data before the upgrade transaction is committed. This will be explained in the following sections.
To take full control over the upgrade transaction, ConfD
must be started using the --start-phase{0,1,2}
command line options. When ConfD is started using the
--start-phase0 option CDB will initiate, and if
it detects an upgrade situation the upgrade transaction will be
created, and all automatic upgrades will be
performed. After which ConfD simply waits, either for a MAAPI
connection or confd --start-phase1.
Whenever changes to the schema cannot be handled automatically, or when the application programmer wants more control over how the data in the upgraded database is populated it is possible to use MAAPI to attach and write to the upgrade transaction in progress (see Chapter 23, The Management Agent API for details on this API).
Using the maapi_attach_init() function
call an external program can attach to the upgrade transaction
during phase0. For example a program that creates the
optional container edible on each flower in
the previous forest example would look like this:
Example 5.11. Writing to an upgrade transaction using MAAPI
int th;
maapi_attach_init(ms, &th);
maapi_set_namespace(ms, th, simple__ns);
maapi_init_cursor(sock, th, &mc, "/forest/flower");
maapi_get_next(&mc);
while (mc.n != 0) {
maapi_create(sock, th, "/forest/flower{%x}/edible", &mc.keys[0]);
maapi_get_next(&mc);
}
maapi_destroy_cursor(&mc);
exit(0);Note the use of the special
maapi_attach_init() function, it attaches the
MAAPI socket to the upgrade transaction (or init transaction) and
returns (through the second argument) the transaction handle we
need to make further MAAPI calls. This special upgrade transaction
is only available during phase0. Once we call confd
--start-phase1 the transaction will be committed.
This method can also be combined with the init file usage
described in the previous section - the data from the init file
will be applied immediately following the automatic conversions at
the beginning of phase0, and the external program can
then use MAAPI to modify or complement the result.
In the previous section we showed how to use MAAPI to access the upgrade transaction after the automatic upgrade had taken place. But this means that CDB has deleted all values that are no longer part of the schema. Well, not quite yet. In start-phase0 it is possible to use all the CDB C-API calls to access the data using the schema from the database as it looked before the automatic upgrade. That is, the complete database as it stood before the upgrade is still available to the application. This allows us to write programs that transfer data in an application specific way between software releases.
Say, for example, that the developers of the Example 5.1, “a simple server data model,
servers.yang” now has decided that having all
servers under one top-element is not enough for their 2.0
release. They want to instead have different categories of servers
under different server types. Also a new IP address is added to
each server, the adminIP. The new version of
servers.yang could then look like this
(version 1.5 has not been merged to the 2.0 branch yet):
Example 5.12. Version 2 of the servers.yang module
module servers {
namespace "http://example.com/ns/servers";
prefix servers;
import ietf-inet-types {
prefix inet;
}
revision "2007-07-15" {
description "Split servers into www and others";
}
revision "2006-09-01" {
description "Initial servers data model";
}
container servers {
list www {
key name;
max-elements 32;
leaf name {
type string;
}
leaf ip {
type inet:ip-address;
mandatory true;
}
leaf port {
type inet:port-number;
mandatory true;
}
leaf adminIP {
type inet:ip-address;
mandatory true;
}
}
list others {
key name;
max-elements 32;
leaf name {
type string;
}
leaf ip {
type inet:ip-address;
mandatory true;
}
leaf port {
type inet:port-number;
mandatory true;
}
leaf adminIP {
type inet:ip-address;
mandatory true;
}
}
}
}
The plan for upgrading users with the old version of the
software is to transfer all servers with their name containing the
letters "www" or whose port is equal to 80, to the
/servers/www subtree, and all the others to the
/servers/others subtree. The new adminIP
element will be initialized to 10.0.0.1 for the first server, and
then increased by one for each server found in the old
database. The code to perform this operation would have to be
written like this:
Example 5.13. The upgrade() function of server_upgrade.c
static struct sockaddr_in addr; /* Keeps address to confd daemon */
/* confd_init() must be called before calling this function */
/* ms and cs are assumed to be valid sockets */
static void upgrade(int ms, int cs)
{
int th;
int i, n;
static struct in_addr admin_ip;
cdb_connect(cs, CDB_READ_SOCKET,
(struct sockaddr *)&addr, sizeof(addr));
cdb_start_session(cs, CDB_RUNNING);
cdb_set_namespace(cs, servers__ns);
maapi_connect(ms, (struct sockaddr *)&addr, sizeof(addr));
maapi_attach_init(ms, &th);
maapi_set_namespace(ms, th, servers__ns);
admin_ip.s_addr = htonl(0x0a000001); /* initialize to 10.0.0.1 */
n = cdb_num_instances(cs, "/servers/server");
printf("servers = %d\n", n);
for (i=0; i < n; i++) {
char name[128];
confd_value_t ip, port, aip;
char *dst;
/* read old database using cdb_* API */
cdb_get_str(cs, name, 128, "/servers/server[%d]/name", i);
cdb_get(cs, &ip, "/servers/server[%d]/ip", i);
cdb_get(cs, &port, "/servers/server[%d]/port", i);
if ((CONFD_GET_UINT16(&port) == 80) ||
(strstr(name, "www") != NULL)) {
dst = "/servers/www{%s}";
} else {
dst = "/servers/others{%s}";
}
/* now create entries in the new database using maapi */
maapi_create(ms, th, dst, name);
maapi_pushd(ms, th, dst, name);
maapi_set_elem(ms, th, &ip, "ip");
maapi_set_elem(ms, th, &port, "port");
CONFD_SET_IPV4(&aip, admin_ip);
maapi_set_elem(ms, th, &aip, "adminIP");
admin_ip.s_addr = htonl(ntohl(admin_ip.s_addr) + 1);
maapi_popd(ms, th);
}
cdb_end_session(cs);
cdb_close(cs);
}
It would of course be wise to add error checks to the code above. Also note that choosing new values for added elements can be done in a number of different ways, perhaps the end-user needs to be prompted, perhaps the data resides elsewhere on the device.
Now assuming the data in CDB is as in the "Initialization data for CDB" figure in the section above, then running the upgrade code would be done in the following order.
$ confd --stop
... Install new versions of software and fxs files ...
$ confd --start-phase0
$ server_upgrade
$ confd --start-phase1
... Start other internal daemons ...
$ confd --start-phase2Finally, after ConfD is up and running after the upgrade the data would look like this.
<servers xmlns="http://example.com/ns/servers">
<www>
<name>www</name>
<ip>192.168.3.4</ip>
<port>88</port>
<adminIP>10.0.0.3</adminIP>
</www>
<www>
<name>www2</name>
<ip>192.168.3.5</ip>
<port>80</port>
<adminIP>10.0.0.4</adminIP>
</www>
<others>
<name>dns</name>
<ip>192.168.3.5</ip>
<port>53</port>
<adminIP>10.0.0.1</adminIP>
</others>
<others>
<name>smtp</name>
<ip>192.168.3.4</ip>
<port>25</port>
<adminIP>10.0.0.2</adminIP>
</others>
</servers>
ConfD does not impose any specific meaning to "version" - any change in the data model is an upgrade situation as far as CDB is concerned. ConfD also does not force the application programmer to handle software releases in a specific way, as each application may have very different needs and requirements in terms of footprint and storage etc.
As an example, we show how to integrate dhcpd - the ISC DHCP daemon - under ConfD.
Assume we have Example 5.14, “A YANG module describing a dhcpd server configuration” in
a file called dhcpd.yang.
Example 5.14. A YANG module describing a dhcpd server configuration
module dhcpd {
namespace "http://example.com/ns/dhcpd";
prefix dhcpd;
import ietf-inet-types {
prefix inet;
}
import tailf-xsd-types {
prefix xs;
}
typedef loglevel {
type enumeration {
enum kern;
enum mail;
enum local7;
}
}
grouping subNetworkType {
leaf net {
type inet:ip-address;
}
leaf mask {
type inet:ip-address;
}
container range {
presence "";
leaf dynamicBootP {
type boolean;
default false;
}
leaf lowAddr {
type inet:ip-address;
mandatory true;
}
leaf hiAddr {
type inet:ip-address;
}
}
leaf routers {
type string;
}
leaf maxLeaseTime {
type xs:duration;
default PT7200S;
}
}
container dhcp {
leaf defaultLeaseTime {
type xs:duration;
default PT600S;
}
leaf maxLeaseTime {
type xs:duration;
default PT7200S;
}
leaf logFacility {
type loglevel;
default local7;
}
container SubNets {
container subNet {
uses subNetworkType;
}
}
container SharedNetworks {
list sharedNetwork {
key name;
max-elements 1024;
leaf name {
type string;
}
container SubNets {
container subNet {
uses subNetworkType;
}
}
}
}
}
}
We use some interesting constructs in this module. We define a grouping and reuse it twice in the module. This is what we do when we want to reuse a data model structure defined somewhere else in the specification.
Now we have a data model which is fully usable with ConfD.
Consider an actual dhcpd.conf file which
looks like:
defaultleasetime 600;
maxleasetime 7200;
subnet 192.168.128.0 netmask 255.255.255.0 {
range 192.168.128.60 192.168.128.98;
}
sharednetwork 22429 {
subnet 10.17.224.0 netmask 255.255.255.0 {
option routers rtr224.example.org;
}
subnet 10.0.29.0 netmask 255.255.255.0 {
option routers rtr29.example.org;
}
}The above dhcp configuration would be represented by an XML structure that looks like this:
<dhcp>
<maxLeaseTime>7200</maxLeaseTime>
<defaultLeaseTime>600</defaultLeaseTime>
<subNets>
<subNet>
<net>192.168.128.0</net>
<mask>255.255.255.0</mask>
<range>
<lowAddr>192.168.128.60</lowAddr>
<highAddr>192.168.128.98</highAddr>
</range>
</subNet>
</subNets>
<sharedNetworks>
<sharedNetwork>
<name>22429</name>
<subNets>
<subNet>
<net>10.17.224.0</net>
<mask>255.255.255.0</mask>
<routers>rtr224.example.org</routers>
</subNet>
<subNet>
<net>10.0.29.0</net>
<mask>255.255.255.0</mask>
<routers>rtr29.example.org</routers>
</subNet>
</subNets>
</sharedNetwork>
</sharedNetworks>
</dhcp>The dhcp server subscribes to configuration changes and reconfigures when notified. For our purposes we write a small program which:
Reads the configuration database.
Writes
/etc/dhcp/dhcpd.confand HUPs the daemon.
The main function looks exactly like the example where we
read the servers database with the exception that we establish a
subscription socket for the path /dhcp instead of
/servers. Whenever any
configuration change occurs for anything related to dhcp, the
program rereads the configuration from CDB, regenerates the
dhcpd.conf file and HUPs the dhcp
daemon.
Reading the dhcp configuration from CDB is done as follows:
static int read_conf(struct sockaddr_in *addr)
{
FILE *fp;
struct confd_duration dur;
int i, n, tmp;
int rsock;
if ((rsock = socket(PF_INET, SOCK_STREAM, 0)) < 0 )
confd_fatal("Failed to open socket\n");
if (cdb_connect(rsock, CDB_READ_SOCKET, (struct sockaddr*)addr,
sizeof (struct sockaddr_in)) < 0)
return CONFD_ERR;
cdb_set_namespace(rsock, dhcpd__ns);
if ((fp = fopen("dhcpd.conf.tmp", "w")) == NULL) {
cdb_close(rsock);
return CONFD_ERR;
}
cdb_get_duration(rsock, &dur, "/dhcp/defaultLeaseTime");
fprintf(fp, "default-lease-time %d\n", duration_to_secs(&dur));
cdb_get_duration(rsock, &dur, "/dhcp/maxLeaseTime");
fprintf(fp, "max-lease-time %d\n", duration_to_secs(&dur));
cdb_get_enum_value(rsock, &tmp, "/dhcp/logFacility");
switch (tmp) {
case dhcpd_kern:
fprintf(fp, "log-facility kern\n");
break;
case dhcpd_mail:
fprintf(fp, "log-facility mail\n");
break;
case dhcpd_local7:
fprintf(fp, "log-facility local7\n");
break;
}
n = cdb_num_instances(rsock, "/dhcp/subNets/subNet");
for (i=0; i<n; i++) {
cdb_cd(rsock, "/dhcp/subNets/subNet[%d]", i);
do_subnet(rsock, fp);
}
n = cdb_num_instances(rsock, "/dhcp/SharedNetworks/sharedNetwork");
for (i=0; i<n; i++) {
unsigned char *buf;
int buflen;
int j, m;
cdb_get_buf(rsock, &buf, &buflen,
"/dhcp/SharedNetworks/sharedNetwork[%d]/name");
fprintf(fp, "shared-network %.*s {\n", buflen, buf);
m = cdb_num_instances(
rsock,
"/dhcp/SharedNetworks/sharedNetwork[%d]/subNets/subNet", i);
for (j=0; j<m; j++) {
cdb_pushd(rsock, "/dhcp/SharedNetworks/sharedNetwork[%d]/"
"subNets/subNet[%d]", i, j);
do_subnet(rsock, fp);
cdb_popd(rsock);
}
fprintf(fp, "}\n");
}
fclose(fp);
return cdb_close(rsock);
}The code first establishes a read socket to CDB. Following
that the code utilizes various CDB read functions to read the
data. Look for example at how we extract the value
/dhcp/defaultLeaseTime from CDB. Looking at Example 5.14, “A YANG module describing a dhcpd server configuration”, we see that the
type of the leaf is xs:duration. There
exists a special type safe version of
cdb_get() which reads a duration value from
the database, which we use as follows:
cdb_get_duration(rsock, &dur, "/dhcp/defaultLeaseTime"); fprintf(fp, "default-lease-time %d\n", duration_to_secs(&dur));
Alternatively, we could have written:
confd_value_t v; struct confd_duration dur; cdb_get(rsock, &v, "/dhcp/defaultLeaseTime"); dur = CONFD_GET_DURATION(&v) fprintf(fp, "default-lease-time %d\n", duration_to_secs(&dur));
We figure out how many shared networks instances there are
through the call to cdb_num_instances() and
then refer to the individual instances through the string syntax
/dhcp/sharedNetworks/sharedNetwork[%d]. The key of an
individual shared network is, according to the data model, the
name element but we do not care about that here, we
iterate through each shared network instance using integers.
These integers which obviously refer to shared network instances
are only valid within this CDB session. Using the normal ConfD key
syntax we can also refer to individual shared networks instances,
e.g. /dhcp/sharedNetworks/sharedNetwork{24-29}. When we
just wish to loop through a set of XML structures it is usually
easier to use the [%d] key syntax.
Also note the call to cdb_get_enum_value(rsock,
&tmp, "/dhcp/logFacility"); which reads an
enumeration. The logFacility element was defined as an
enumerated type. Enumerations are represented as integers, both in
our C code, but more importantly they are also represented as
integers when we store the string in the CDB database on
disk. I.e., we will not store the "logFacility" string "local7"
over and over again on disk. Similarly in our C code we also get a
(switchable) integer value as returned from
cdb_get_enum_value().
Especially interesting in the
read_conf() code above is how we use
cdb_pushd() in combination with
cdb_popd(). The
cdb_pushd() functions works like
cdb_cd(), i.e. it changes the position in the
data tree, with the difference that we can call
cdb_popd() and return to where we were
earlier in the XML tree. We traverse the SharedNetworks
and execute
cdb_pushd(rsock, "/dhcp/SharedNetworks/sharedNetwork[%d]/"
"subNets/subNet[%d]", i, j);
do_subnet(rsock, fp);
cdb_popd(rsock);Where the function do_subnet() reads in
a subnet structure from CDB. The do_subnet()
code works on relative paths as opposed to absolute paths.
The purpose of the example is to show how we can reuse the
function do_subnet() and call it at different
points in the XML tree. The function itself does not know whether
it is reading a subnet under /dhcp/subNets or under
/dhcp/SharedNetworks/sharedNetwork/subNets. Also
noteworthy is that fact that utilizing pushd/popd makes for more
efficient code since the part of the path leading up to the pushed
element is already parsed and verified to be correct. Thus the
parsing and path verification does not have to be executed for
each and every element.
static void do_subnet(int rsock, FILE *fp)
{
struct in_addr ip;
char buf[BUFSIZ];
struct confd_duration dur;
char *ptr;
cdb_get_ipv4(rsock, &ip, "net");
fprintf(fp, "subnet %s ", inet_ntoa(ip));
cdb_get_ipv4(rsock, &ip, "mask");
fprintf(fp, "netmask %s {\n", inet_ntoa(ip));
if (cdb_exists(rsock, "range") == 1) {
int bool;
fprintf(fp, " range ");
cdb_get_bool(rsock, &bool, "range/dynamicBootP");
if (bool) fprintf(fp, " dynamic-bootp ");
cdb_get_ipv4(rsock, &ip, "range/lowAddr");
fprintf(fp, " %s ", inet_ntoa(ip));
cdb_get_ipv4(rsock, &ip, "range/hiAddr");
fprintf(fp, " %s ", inet_ntoa(ip));
fprintf(fp, "\n");
}
cdb_get_str(rsock, &buf[0], BUFSIZ, "routers");
/* replace space with comma */
for (ptr = buf; ptr != '\0'; ptr++) {
if (*ptr == ' ')
*ptr = ',';
}
fprintf(fp, "routers %s\n", buf);
cdb_get_duration(rsock, &dur, "maxLeaseTime");
fprintf(fp, "max-lease-time %d\n", duration_to_secs(&dur));
}Finally, we define the code fragment that must be executed by our application when there is IO ready to read on the subscription socket:
if (set[1].revents & POLLIN) {
int sub_points[1];
int reslen;
if ((status = cdb_read_subscription_socket(subsock,
&sub_points[0],
&reslen)) != CONFD_OK) {
fprintf(stderr, "terminate sub_read: %d\n", status);
exit(1);
}
if (reslen > 0) {
if ((status = read_conf(&addr)) != CONFD_OK) {
fprintf(stderr, "Terminate: read_conf %d\n", status);
exit(1);
}
}
rename("dhcpd.conf.tmp", "/etc/dhcpd.conf");
system("killall -HUP dhcpd");
if ((status = cdb_sync_subscription_socket(subsock,
CDB_DONE_PRIORITY))
!= CONFD_OK) {
fprintf(stderr, "failed to sync subscription: %d\n", status);
exit(1);
}
}