Table of Contents
- 6.1. Introduction to Operational Data
- 6.2. Reading Statistics Data
- 6.3. Callpoints and Callbacks
- 6.4. Data Callbacks
- 6.5. User Sessions and ConfD Transactions
- 6.6. C Example with Operational Data
- 6.7. The Protocol and a Library Threads Discussion
- 6.8. Operational data in CDB
- 6.9. Delayed Replies
- 6.10. Caching Operational Data
- 6.11. Operational data lists without keys
In Chapter 3, The YANG Data Modeling Language we showed how to define data models in YANG. In Chapter 5, CDB - The ConfD XML Database we showed how to use CDB and also how to interface CDB to external daemons. In this chapter, we show how to write instrumentation code for read-only operational and statistics data.
Operational data is typically not kept in a database but read at runtime by instrumentation functions. This would for example be statistics counters contained inside the managed objects themselves. In this chapter we will show how to write such instrumentation functions in C.
An alternative approach to runtime operational data is to store the operational in CDB using a write interface. This will be described in Section 6.8, “Operational data in CDB”.
The configuration of the network device is modeled by a YANG module. This describes the data model of the device. We also need to write YANG modules for our operational data.
In the YANG data model, there can be restrictions on valid operational data. For example, a list might have a "max-elements" constraint, or a "must" expression associated with it. For performance reasons, ConfD does not check these constraints. It is assumed that the application code that generates operational data enforces the constraints.
Normally, operational data is strictly read-only. If the operational state of the device needs to be modified, it is typically done through special operations (rpc or actions in NETCONF, or special commands in the CLI). But this imposes a problem with protocols like SNMP, that do not have a mechanism to invoke arbitrary operations. In SNMP, this is solved by writing values to special objects, called writable operational objects. These objects are implemented in the same way as writable configuration data, described in Section 7.8, “Writable operational data”, and the section called “Writable MIB objects”.
A very common situation is that we wish to expose statistics data from the device. Consider for example the output of the netstat -i command.
#root netstat -i Iface MTU Met RX-OK RX-ERR RX-DRP TX-OK TX-ERR TX-DRP Flg eth0 1500 0 212684 0 0 142470 0 0 BMRU lo 16436 0 2077 0 0 2077 0 0 LRU
This is useful information to expose to the Web UI, the CLI or a management application running NETCONF.
To address this we must do two things; the statistics information must be modeled in a YANG module:
Example 6.1. netstat.yang
container ifaces {
config false;
list iface {
key name;
max-elements 1024;
leaf name {
type string;
}
leaf mtu {
type uint32;
}
leaf metric {
type uint64;
}
leaf rx_ok {
type uint64;
}
leaf rx_err {
type uint64;
}
leaf rx_drp {
type uint64;
}
leaf tx_ok {
type uint64;
}
leaf tx_err {
type uint64;
}
leaf tx_drop {
type uint64;
}
leaf flag {
type string;
}
}
}The above simple one-to-one mapping of the netstat -i output and a YANG data model might suffice for our needs. It can be refined later.
The second thing that must be done is to write C code that parses the netstat -i output. Finally we must connect that C code to ConfD. That procedure will be fully described in this chapter.
Thus we need to:
Write a YANG module describing our operational data (see Chapter 3, The YANG Data Modeling Language).
Write a mapping between the data model and the operational data as represented on the target device. The mapping is specified inside the data model itself, using callbacks to C.
The data model indicates where to invoke callbacks by
annotation with callpoints. A callpoint has a name
which later can be used by an external program to connect to
that named point.
Tip
We can always define callpoints in a separate YANG
module by using the tailf:annotate extension as
described in the tailf_yang_extensions(5) manual page.
This way we can keep the data model free from implementation
specific details.
Assume that we wish to model the ARP table of the host:
Example 6.2. ARP table YANG module
module arpe {
namespace "http://tail-f.com/ns/example/arpe";
prefix arpe;
import ietf-inet-types {
prefix inet;
}
import tailf-common {
prefix tailf;
}
container arpentries {
config false;
tailf:callpoint arpe;
list arpe {
key "ip ifname";
max-elements 1024;
leaf ip {
type inet:ip-address;
}
leaf ifname {
type string;
}
leaf hwaddr {
type string;
mandatory true;
}
leaf permanent {
type boolean;
mandatory true;
}
leaf published {
type boolean;
mandatory true;
}
}
}
}
The arpe callpoint will invoke callbacks in external
programs that has registered itself with the name "arpe". The
programs use the API in the libconfd.so library to
register themselves under different callpoints.
The config false; statement instructs ConfD that the
entire arpentries container is non-configuration
data. Data below that point is not part of the configuration;
rather it should be viewed as ephemeral read-only data.
Assume we have the above YANG module loaded in ConfD. Furthermore that ConfD receives a NETCONF "get" request like:
<rpc xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="1"> <get/> </rpc>
ConfD is configured to accept a number of arpe list
entries contained inside an arpentries container. It
does not know which arpe entries reside on the device
though. With the above NETCONF request, the task for ConfD is
to produce an XML structure containing all the arpe
entries on the device.
This is solved by letting the application register itself with
a set of callback C functions under the callpoint. The callback
C functions do things like get_next(),
get_elem() and so forth.
There can be several different C programs on the same device
which register themselves under different callpoints.
These C programs that register with ConfD are referred to as
daemons.
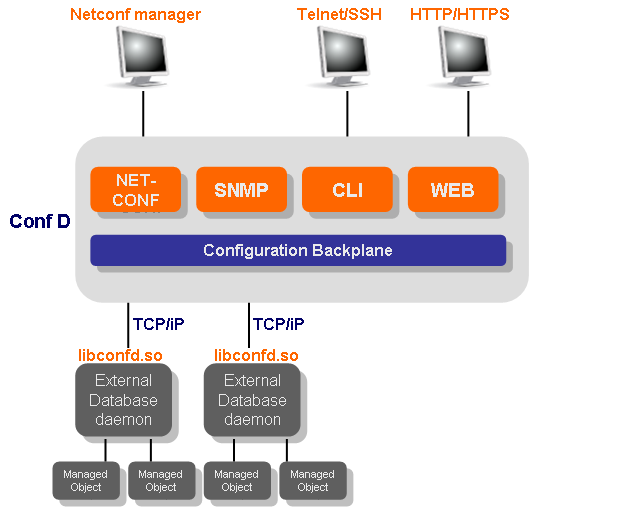 |
Daemons using libconfd.so to connect to ConfD.
In the above picture we show how two separate C programs
(daemons) connect to ConfD using the libconfd.so
shared library.
Each callpoint in a YANG module must have an associated set of callback functions. The following data callback functions are required for operational data:
get_next()This callback is invoked repeatedly to find out which keys exist for a certain list. ConfD will invoke the callback as a means to iterate through all entries of the list, in this case all
arpeentries. For example, assume that the ARP table on the device looks as:Example 6.3. Populated ARP table
<arpe:arpentries xmlns:arpe="http://tail-f.com/ns/example/arpe/1.0"> <arpe:arpe> <arpe:ip>192.168.1.1</arpe:ip> <arpe:ifname>eth0</arpe:ifname> <arpe:hwaddr>00:30:48:88:1F:E2</arpe:hwaddr> <arpe:permanent>false</arpe:permanent> <arpe:published>false</arpe:published> </arpe:arpe> <arpe:arpe> <arpe:ip>192.168.1.42</arpe:ip> <arpe:ifname>eth0</arpe:ifname> <arpe:hwaddr>00:30:48:88:1F:C5</arpe:hwaddr> <arpe:permanent>false</arpe:permanent> <arpe:published>false</arpe:published> </arpe:arpe> </arpe:arpentries>The job of the
get_next()callback would be to return the first key on the first invocation, namely the pair "192.168.1.1", "eth0" and then subsequently the remaining keys until there are no more keys. (The data model says that we have two keys,ipandifname.)get_elem()This callback is invoked by ConfD when ConfD needs to read the actual value of a leaf element. We must also implement the
get_elem()callback for the keys. ConfD invokesget_elem()on a key as an existence test.exists_optional()This callback is called for all typeless and optional elements, i.e.
presencecontainers and leafs of typeempty. For example the YANG module fragment:container bs { presence "bs"; config false; tailf:callpoint bcp; leaf foo { type string; } }If we do not have any typeless optional elements in our data model we need not implement this callback and can set it to NULL. A detailed description of this callback can be found in the confd_lib_dp(3) manual page.
We also have a number of additional optional callbacks that may be implemented for efficiency reasons. The precise usage of these optional callbacks is described in the man page confd_lib_dp(3).
get_object()If this optional callback is implemented, the work of the callback is to return an entire
object, i.e. a list entry. In this case all the five elements contained in anarpeentry - namely theip,ifname,hwaddr,permanentand finallypublishedleafs.num_instances()When ConfD needs to figure out how many entries we have for a list, by default ConfD will repeatedly invoke the
get_next()callback. If this callback is registered, it will be called instead.get_next_object()This optional callback combines
get_next()andget_object()into a single callback. This callback only needs to be implemented when it is very important to be able to traverse a table fast.find_next()This callback primarily optimizes cases where ConfD wants to start a list traversal at some other point than at the first entry of the list. It is mainly useful for lists with a large number of entries. If it is not registered, ConfD will use a sequence of
get_next()calls to find the desired list entry.find_next_object()This callback combines
find_next()andget_object()into a single callback.
In this section we will describe a number of new concepts. We will define what we mean by a user session and what ConfD transactions are. This will be further explained in Chapter 7, The external database API.
A user session corresponds directly to an SSH/SSL session from a management station to ConfD. A user session is associated with such data as the IP address of the management station and the user name of the user who started the session, independent of northbound agent.
The user session data is always available to all callback functions.
A new transaction is started whenever an agent tries to read operational data. For each transaction two user defined callbacks are potentially invoked:
init()From the daemon's point of view, this callback will be invoked when a transaction starts. However as an optimization, ConfD will delay the invocation for a given daemon until the point where some data needs to be read, i.e. just before the first
get_next(),get_elem(), etc callback.finish()This callback gets invoked at the end of the transaction, if
init()has been invoked. This is a good place to deallocate any local resources for the transaction. This callback is optional.
The "lazy" invocation of init() means that for a transaction
where none of the operational data provided by a given daemon
is accessed, that daemon will not have any callbacks at all
invoked.
Assume we want to provide the state of the current ARP table
on the device. To do this we need to write a YANG module which
models an ARP table, and then write C functions which
populates the corresponding XML tree. We use the YANG module
from the previous section and save it to a file
arpe.yang and compile the module using the
confdc compiler as:
# confdc -c arpe.yang # confdc --emit-h arpe.h arpe.fxs
The --emit-h option to confdc
is used to generate a header
file. Thus, in our example the generated file will be
called arpe.h. The generated header file contains
a mapping from the strings
found in the data model such as ip or
permanent to integer values.
Finally we must instruct ConfD where to find the newly
generated schema file. Using the default ConfD
configuration, ConfD looks for schema (.fxs) files under
/etc/confd:
# cp arpe.fxs /etc/confd # confd
After loading arpe.fxs, ConfD runs with the newly
generated data model. Next we need to write the C program
which provides the ARP data by means of C callback
functions.
An actual running version of this example can be found in
the intro/5-c_stats directory in the examples
in the distribution release. We will walk through this C program
here.
First we need to include confd_lib.h and
confd_dp.h which are part of a
ConfD release, as well as the newly generated
arpe.h.
See confdc
(1) for details.
#include <confd_lib.h> #include <confd_dp.h> #include "arpe.h"
We use a couple of global variables as well as a structure which represents an ARP entry.
/* Our daemon context as a global variable */
static struct confd_daemon_ctx *dctx;
static int ctlsock;
static int workersock;
struct aentry {
struct in_addr ip4;
char *hwaddr;
int perm;
int pub;
char *iface;
struct aentry *next;
};
struct arpdata {
struct aentry *arp_entries;
struct timeval lastparse;
};
The struct confd_daemon_ctx *dctx is a daemon context. It is a data structure which is passed to virtually all the functions.
We are ready for the main() function. There we will
initialize the library, connect to the ConfD daemon and
install a number of callback functions as pointers to C
functions. Remember the architecture of this system, ConfD
executes as a common daemon, and the program we are writing
executes outside the address space of ConfD. Our program
links with the ConfD library (libconfd.so) which
manages the protocol between our application and ConfD.
int main(int argc, char *argv[])
{
struct sockaddr_in addr;
int debuglevel = CONFD_TRACE;
struct confd_trans_cbs trans;
struct confd_data_cbs data;
memset(&trans, 0, sizeof (struct confd_trans_cbs));
trans.init = s_init;
trans.finish = s_finish;
memset(&data, 0, sizeof (struct confd_data_cbs));
data.get_elem = get_elem;
data.get_next = get_next;
strcpy(data.callpoint, arpe__callpointid_arpe);
/* initialize confd library */
confd_init("arpe_daemon", stderr, debuglevel);
addr.sin_addr.s_addr = inet_addr("127.0.0.1");
addr.sin_family = AF_INET;
addr.sin_port = htons(CONFD_PORT);
if (confd_load_schemas((struct sockaddr*)&addr,
sizeof (struct sockaddr_in)) != CONFD_OK)
confd_fatal("Failed to load schemas from confd\n");
if ((dctx = confd_init_daemon("arpe_daemon")) == NULL)
confd_fatal("Failed to initialize confdlib\n");
/* Create the first control socket, all requests to */
/* create new transactions arrive here */
if ((ctlsock = socket(PF_INET, SOCK_STREAM, 0)) < 0 )
confd_fatal("Failed to open ctlsocket\n");
if (confd_connect(dctx, ctlsock, CONTROL_SOCKET, (struct sockaddr*)&addr,
sizeof (struct sockaddr_in)) < 0)
confd_fatal("Failed to confd_connect() to confd \n");
/* Also establish a workersocket, this is the most simple */
/* case where we have just one ctlsock and one workersock */
if ((workersock = socket(PF_INET, SOCK_STREAM, 0)) < 0 )
confd_fatal("Failed to open workersocket\n");
if (confd_connect(dctx, workersock, WORKER_SOCKET,(struct sockaddr*)&addr,
sizeof (struct sockaddr_in)) < 0)
confd_fatal("Failed to confd_connect() to confd \n");
if (confd_register_trans_cb(dctx, &trans) == CONFD_ERR)
confd_fatal("Failed to register trans cb \n");
if (confd_register_data_cb(dctx, &data) == CONFD_ERR)
confd_fatal("Failed to register data cb \n");
if (confd_register_done(dctx) != CONFD_OK)
confd_fatal("Failed to complete registration \n");
At this point we have registered our callback functions for
data manipulations under the arpe callpoint. Whenever
data needs to manipulated below that callpoint our C
callback functions should be invoked. The
confd_register_done() call tells ConfD
that we are done
with the callback registrations - no callbacks will be invoked
before we issue this call.
The arpe__callpointid_arpe symbol that is
used for the callpoint element in the data
callback registration is one of the definitions in the
generated arpe.h file. It just maps to
the string "arpe" that we could have used
instead, but by using the symbol we make sure that if the name
given with the tailf:callpoint statement in the
YANG module is changed, without a corresponding change in the C
code, the problem is detected at compile time.
We have also created one control socket and one worker
socket. These are sockets owned by the application and they
should be added to the poll() or
select() set
of the application.
All new requests that arrive from ConfD arrive on the
control socket. As we will see, the
init() callback
must call the API function
confd_trans_set_fd() which
will assign a worker socket to the transaction. All further
requests and replies for this transaction will be sent on
the worker socket. We can have several worker sockets and
they can run in different operating system threads than the
thread owning the control socket.
The poll loop could look like:
while(1) {
struct pollfd set[2];
int ret;
set[0].fd = ctlsock;
set[0].events = POLLIN;
set[0].revents = 0;
set[1].fd = workersock;
set[1].events = POLLIN;
set[1].revents = 0;
if (poll(set, sizeof(set)/sizeof(*set), -1) < 0) {
perror("Poll failed:");
continue;
}
/* Check for I/O */
if (set[0].revents & POLLIN) {
if ((ret = confd_fd_ready(dctx, ctlsock)) == CONFD_EOF) {
confd_fatal("Control socket closed\n");
} else if (ret == CONFD_ERR && confd_errno != CONFD_ERR_EXTERNAL) {
confd_fatal("Error on control socket request: %s (%d): %s\n",
confd_strerror(confd_errno), confd_errno, confd_lasterr());
}
}
if (set[1].revents & POLLIN) {
if ((ret = confd_fd_ready(dctx, workersock)) == CONFD_EOF) {
confd_fatal("Worker socket closed\n");
} else if (ret == CONFD_ERR && confd_errno != CONFD_ERR_EXTERNAL) {
confd_fatal("Error on worker socket request: %s (%d): %s\n",
confd_strerror(confd_errno), confd_errno, confd_lasterr());
}
}
}
The crucial function above is confd_fd_ready(). When
either of the (in this case, two) sockets from the
application to ConfD are ready to read, the application is
responsible for invoking the confd_fd_ready()
function. This function will read data from the socket,
unmarshal that data and invoke the right callback
function with the right arguments.
We have installed two transaction callbacks:
init()
and finish(), and also two data callbacks:
get_next() and get_elem().
The two transaction callbacks look like:
static int s_init(struct confd_trans_ctx *tctx)
{
struct arpdata *dp;
if ((dp = malloc(sizeof(struct arpdata))) == NULL)
return CONFD_ERR;
memset(dp, 0, sizeof(struct arpdata));
if (run_arp(dp) == CONFD_ERR) {
free(dp);
return CONFD_ERR;
}
tctx->t_opaque = dp;
confd_trans_set_fd(tctx, workersock);
return CONFD_OK;
}
static int s_finish(struct confd_trans_ctx *tctx)
{
struct arpdata *dp = tctx->t_opaque;
if (dp != NULL) {
free_arp(dp);
free(dp);
}
return CONFD_OK;
}
The init() callback reads the ARP table calling a
function run_arp() and stores a local copy of a parsed
ARP table in the transaction context. This data structure
(struct confd_trans_ctx *tctx) is allocated by the
library and used throughout the entire transaction. The
t_opaque field in the transaction context is meant to
be used by the application to store transaction local data.
A naive version of run_arp() could call
popen(3) on the command arp -an and parse the
output:
# arp -an ? (192.168.128.33) at 00:40:63:C9:79:FC [ether] on eth1 ? (217.209.73.1) at 00:02:3B:00:3B:67 [ether] on eth0
The parsed ARP table created by run_arp()
is ordered by increasing key values, since ConfD expects us to
return entries in that order when traversing the list.
There may be several ConfD transactions running in parallel and some transactions may have been initiated from the CLI and the current ARP data may be stale or may be nonexistent.
The init() callback must also indicate to the library
which socket should be used for all future traffic for this
transaction. In our case, we have just one option, namely
the single worker socket we created. This is done through
the call to confd_trans_set_fd(). Also, the
init() callback was fed a transaction context
parameter. This structure is allocated by the library and
fed to each and every callback function executed during the
life of the transaction. The structure is defined in
confd_lib.h.
Our finish() function cleans up everything.
The data callbacks look like:
static int get_next(struct confd_trans_ctx *tctx,
confd_hkeypath_t *keypath,
long next)
{
struct arpdata *dp = tctx->t_opaque;
struct aentry *curr;
confd_value_t v[2];
if (next == -1) { /* first call */
if (need_arp(dp)) {
if (run_arp(dp) == CONFD_ERR)
return CONFD_ERR;
}
curr = dp->arp_entries;
} else {
curr = (struct aentry *)next;
}
if (curr == NULL) {
confd_data_reply_next_key(tctx, NULL, -1, -1);
return CONFD_OK;
}
/* 2 keys */
CONFD_SET_IPV4(&v[0], curr->ip4);
CONFD_SET_STR(&v[1], curr->iface);
confd_data_reply_next_key(tctx, &v[0], 2, (long)curr->next);
return CONFD_OK;
}
struct aentry *find_ae(confd_hkeypath_t *keypath, struct arpdata *dp)
{
struct in_addr ip = CONFD_GET_IPV4(&keypath->v[1][0]);
char *iface = (char*)CONFD_GET_BUFPTR(&keypath->v[1][1]);
struct aentry *ae = dp->arp_entries;
while (ae != NULL) {
if (ip.s_addr == ae->ip4.s_addr &&
(strcmp(ae->iface, iface) == 0) )
return ae;
ae=ae->next;
}
return NULL;
}
/* Keypath example */
/* /arpentries/arpe{192.168.1.1 eth0}/hwaddr */
/* 3 2 1 0 */
static int get_elem(struct confd_trans_ctx *tctx,
confd_hkeypath_t *keypath)
{
confd_value_t v;
struct aentry *ae = find_ae(keypath, tctx->t_opaque);
if (ae == NULL) {
confd_data_reply_not_found(tctx);
return CONFD_OK;
}
switch (CONFD_GET_XMLTAG(&(keypath->v[0][0]))) {
case arpe_hwaddr:
if (ae->hwaddr == NULL) {
confd_data_reply_not_found(tctx);
return CONFD_OK;
}
CONFD_SET_STR(&v, ae->hwaddr);
break;
case arpe_permanent:
CONFD_SET_BOOL(&v, ae->perm);
break;
case arpe_published:
CONFD_SET_BOOL(&v, ae->pub);
break;
case arpe_ip:
CONFD_SET_IPV4(&v, ae->ip4);
break;
case arpe_ifname:
CONFD_SET_STR(&v, ae->iface);
break;
default:
return CONFD_ERR;
}
confd_data_reply_value(tctx, &v);
return CONFD_OK;
}
The above code needs a bit of explaining. Before doing this we need to look at how the confd_hkeypath_t data type works.
All the different data manipulation callbacks get a hashed
keypath as a parameter. For example when a daemon gets
invoked in get_elem() and ConfD wants to read the
published element for a specific arp entry, the textual
representation of the hkeypath is
/arpentries/arpe{1.2.3.4 eth0}/published.
The C representation of a hashed keypath is a fixed size array of values, as in:
typedef struct confd_hkeypath {
confd_value_t v[MAXDEPTH][MAXKEYLEN];
int len;
} confd_hkeypath_t;
The keypath is fed in the reverse order to the application,
thus - when ConfD wants to read
/arpentries/arpe{1.2.3.4 eth0}/published,
the following holds for the
keypath:
keypath->v[0][0]is the XML element, namelypublished.keypath->v[1][0]is the first key one step up, in our case the IP address1.2.3.4.keypath->v[1][1]is the second key one step up, in our case the interface nameeth0.keypath->v[2][0]is the XML element two steps up, namelyarpe.keypath->v[3][0]is the XML element three steps up, namelyarpentries. The top level element. This item could also have been obtained through the expressionkeypath->v[keypath->len - 1][0].
The actual values are represented as a union struct defined
in confd_lib.h. The confd_value_t data type can
represent all ground data types such as strings, integers,
but also slightly more complex data types such as IP
addresses and the various date and time data types found in
XML schema.
confd_lib.h defines a set of macros to set and get the
actual values from confd_value_t variables. For
example this code sets and gets an individual value:
confd_value_t myval; int i = 99; CONFD_SET_INT32(&myval, i); assert(99 == CONFD_GET_INT32(&myval));
One important variant of confd_value_t is string.
All data values which are of type string, or of a
type derived from string,
are passed from ConfD to the application as
NUL terminated strings. Thus confd_value_t contains
a length indicator and is NUL terminated.
All strings consist of an unsigned char* pointer and a length indicator. To copy such a string into a local buffer we need to write code like:
char *mybuf = malloc(CONFD_GET_BUFSIZE(someval)+1); strcpy(mybuf, (char*)CONFD_GET_BUFPTR(someval));
On the other hand, when the application needs to reply with a string value to ConfD, the application can choose to use either a NUL terminated string or a buffer with a length indicator using the following macros:
confd_value_t myval; CONFD_SET_STR(&myval, "Frank Zappa");
or
confd_value_t myval; CONFD_SET_BUF(&myval, buf, buflen);
XML tags are also represented as
confd_value_t. Remember that we said that
keypath->v[0][0] was the actual XML element. Also
remember that confdc generated a .h file. The
arpe.h file, containing all the XML elements from
arpe.yang as integers. The following code uses that
to switch on the XML tag:
switch (CONFD_GET_XMLTAG(&(keypath->v[0][0]))) {
case arpe_hwaddr:
if (ae->hwaddr == NULL) {
confd_data_reply_not_found(tctx);
return CONFD_OK;
}
CONFD_SET_STR(&v, ae->hwaddr);
break;
case arpe_permanent:
CONFD_SET_BOOL(&v, ae->perm);
break;
Each keypath has a textual representation, so we can format
a keypath by means of the API call confd_pp_kpath().
A hashed keypath, a confd_hkeypath_t, represents a
unique path down through the XML tree and it is easy and
efficient to walk the path through switch statements
since the individual XML elements in the path are integers.
The purpose of both functions, (get_next() and
get_elem()), is to return data back to ConfD. Data
is not returned explicitly through return values from the
callback functions, but rather through explicit API calls.
So when the application gets invoked in get_elem()
via a call to confd_fd_ready(), we need to return a
single value to ConfD. We do this through the call to
confd_data_reply_value(). Thus the following code
snippet returns an integer value to ConfD.
confd_value_t myval; CONFD_SET_INT32(&myval, 7777); confd_data_reply_value(tctx, &myval);
The get_elem() callback is also used as an existence
test by ConfD. It may seem redundant to implement the
get_elem() callback for a keypath such as:
"/arpentries/arpe{1.2.3.4 eth0}/ip" since the only
possible reply can be the IP address "1.2.3.4" which is
already part of the keypath. However, the user can enter any
random path in the CLI and ConfD uses the get_elem()
callback to check whether an entry exists or not.
If the entry does not exist, the callback should call
confd_data_reply_not_found() and then return
CONFD_OK. This is not an error.
The API is fully documented in the confd_lib_dp(3) manual page.
The get_next() callback gets invoked when ConfD needs
to read all the keys of a certain list such as
our ARP entries. The next parameter will have the
value -1 on the first invocation to get_next().
This invocation needs to return the
first key in the ordered list created by
run_arp().
In our case, with our ARP entries, we have multiple
keys. According to the data model the pair of the interface
name and the IP address makes up the key. Thus we need to
return two values:
CONFD_SET_IPV4(&v[0], curr->ip4);
CONFD_SET_STR(&v[1], curr->iface);
confd_data_reply_next_key(tctx, &v[0], 2, (long)curr->next);
The last parameter to confd_data_reply_next_key() is
a long integer which will be fed to us as the next
parameter on the subsequent call. We cast the pointer to the
next struct aentry* as a long.
In the above code, we registered a single set of callback C
functions on the callpoint. Sometimes we may have different
daemons that handle different kinds of data, but under the
same callpoint. Say for example that we have a list of
interfaces, VLAN interfaces and regular interfaces. We have
different software modules which handle the VLAN interfaces
and the regular interfaces. In this case, we may use
confd_register_range_data_cb() (See
confd_lib_dp(3)) which makes it
possible to install a
set of callbacks on a range of keys, for example one set of
callbacks for eth0 to
ethX and another set
of callbacks in the range from vlan0 to
vlanX.
Also notable is the consistency of the data. If we use CDB
to store our configuration data and we use this external
data API to deliver statistics data which is volatile we
must choose whether we want to deliver an exact snapshot of
the statistics data or not. ConfD will consecutively call
get_next() to gather all the keys for a set of
dynamic elements. A moment later ConfD will invoke
get_elem() or get_object() to gather the
actual data. If this data no longer exists, the application
can invoke confd_data_reply_not_found() and all is
fine.
An alternative for the application if we must always return
consistent snapshots, is to gather and buffer all the data
in the init() callback and then return both
get_next() data as well as get_elem() data
from those internal data structures. This data can be stored
in the t_opaque field in the transaction context and
be released in the finish() callback.
In our example code above we have chosen the latter
approach. Also notable is the check for age of data at the
beginning of get_next(). A NETCONF transaction is
typically short lived, whereas a CLI transaction remains
live for as long as the user is logged in. Thus we may have
to refresh the locally stored ARP table if it is deemed to
be too old.
We start this section with a picture showing the sequence of events that occur when the user defined callback functions get invoked by the library.
Event chain that triggers user callbacks
On the library side we have one control socket and one or more worker sockets. The idea behind this architecture is that it shall be possible to have a software architecture, whereby a main thread owns the control socket, and we also have a set of worker threads, each owning one or more worker sockets. A request to execute something arrives from ConfD on the control socket, and the thread owning the control socket, the main thread, can then decide to assign a worker thread for that particular activity, be it a validation, a new transaction or the invocation of an action. The owner of the control socket must thus have a mapping between worker sockets and thread workers. This is up to the application to decide.
The downside of the architecture proposed above is complexity, whereas the upside is that regardless of how long time it takes to execute an individual request from ConfD, the data provider is always ready to accept and serve new callback requests from ConfD.
The case for a multi threaded dataprovider maybe isn't as
strong as one could think. Say that we have a statistics data
provider which lists a very long list of statistics items, e.g.
a huge routing table. If a CLI user invokes the command to
show all routing table entries, there will be a long series
of get_next() and get_elem() callback
invocations. As long as the application is still polling
the control socket, other northbound agents can very well
sneak in and execute their operations while the routing
table is being displayed. For example another CLI user
issuing a request to reboot the host, will get his reboot
request served at the same time as the first CLI user is
displaying the large routing table.
A data provider with just one thread, one control socket and
one worker socket will never hang longer than it takes to
execute a single callback invocation, e.g. a single invocation
of get_elem(),
validate() or
action(). In many cases it will still be
a good design to use at least one thread for the control
socket and one for the worker socket - this will allow for
control socket requests to be handled quickly even if the
data callbacks require more processing time. If we have
long-running action callbacks (e.g. file download),
multi-threading may be essential, see Section 11.2.2, “Using Threads”.
The intro/9-c_threads example in the
ConfD examples collection shows one way to use
multi-threading in a daemon that implements both operational
data callbacks and action callbacks. It has one thread for
the control socket and only a single worker socket/thread for
the data callbacks, while multiple worker sockets/threads are
used to handle the action callbacks.
When we use multiple threads, it is important to remember that threads can not "share" socket connections to ConfD. For the data provider API, this is basically fulfilled automatically, as we will not have multiple threads polling the same socket. But when we use e.g. the CDB or MAAPI APIs, the application must make sure that each thread has its own sockets. I.e. the ConfD API functions are thread-safe as such, but multiple threads using them with the same socket will have unpredictable results, just as multiple threads using the read() and write() system calls on the same file descriptor in general will. In the ConfD case, one thread may end up getting the response to a request from another, or even a part of that response, which will result in errors that can be very difficult to debug.
It is possible to use CDB to store not only the configuration data but also operational data. Depending on the application and the underlying architecture it may be easier for some of the managed objects to write their operational data into CDB. Depending on the type of data, this would typically be done either at regular intervals or whenever there is a change in the data. If this is done, no instrumentation functions need to be written. The operational data then resides in CDB and all the northbound agents can read the operational data automatically from CDB.
Similar to the CDB read interface, we need to create a CDB socket and also start a CDB session on the socket before we can write data
The necessary steps are:
cdb_connect()cdb_start_session()followed bycdb_set_namespace()A series of calls to one or several of the CDB set functions,
cdb_set_elem(),cdb_create(),cdb_delete()cdb_set_object()orcdb_set_values()These functions are described in detail in the confd_lib_cdb(3) manual page.
A call to
cdb_end_session()
It is also possible to load operational data from an XML
file into CDB using the function
cdb_load_file(), see the confd_lib_cdb(3) manual page. A command
line utility called confd_load can also be
used, see confd_load(1).
We use the tailf:cdb-oper statement to indicate
that operational data should be stored in CDB, see the tailf_yang_extensions(5) manual page.
The data can be either persistent,
i.e. stored on disc, or volatile, i.e. stored in RAM only -
this is controlled by the tailf:persistent
substatement to tailf:cdb-oper.
As a realistic example we model IP traffic statistics in a
Linux environment. We have a list of interfaces, stored in
CDB and then for each interface we have a statistics part.
This example can be found in
cdb_oper/ifstatus in the examples
collection. This is what our data model looks like:
module if {
namespace "http://tail-f.com/ns/example/if";
prefix if;
import ietf-inet-types {
prefix inet;
}
import tailf-common {
prefix tailf;
}
container interfaces {
list interface {
key name;
max-elements 1024;
leaf name {
type string;
}
list address {
key name;
max-elements 64;
leaf name {
type inet:ipv4-address;
}
leaf prefix-length {
type int32;
mandatory true;
}
}
container status {
config false;
tailf:cdb-oper;
container receive {
leaf bytes {
type uint64;
mandatory true;
}
leaf packets {
type uint64;
mandatory true;
}
leaf errors {
type uint32;
mandatory true;
}
leaf dropped {
type uint32;
mandatory true;
}
}
container transmit {
leaf bytes {
type uint64;
mandatory true;
}
leaf packets {
type uint64;
mandatory true;
}
leaf errors {
type uint32;
mandatory true;
}
leaf dropped {
type uint32;
mandatory true;
}
leaf collisions {
type uint32;
mandatory true;
}
}
}
}
}
}
Note the element /interfaces/interface/status, it
has the substatement config false; and below it we find
a tailf:cdb-oper; statement. If we had implemented this
operational data using the techniques from the previous
sections in this chapter, we would have had to write
instrumentation callback functions for the above operational
data. For example get_elem() which would then be
given a path, e.g.
/interfaces/interface{eth0}/status/receive/bytes
When we use the tailf:cdb-oper; statement these
instrumentation callbacks are automatically provided
internally by ConfD. The downside is that we must populate
the CDB data from the outside.
A function which reads network traffic statistics data and updates CDB according to the above data model is:
#define GET_COUNTER() { \
if ((p = strtok(NULL, " \t")) == NULL) \
continue; \
counter = atoll(p); \
}
static int update_status(int sock)
{
FILE *proc;
int ret;
char buf[BUFSIZ];
char *ifname, *p;
long long counter;
confd_value_t val[1 + 4 + 1 + 5];
int i;
if ((ret = cdb_start_session(sock, CDB_OPERATIONAL)) != CONFD_OK)
return ret;
if ((ret = cdb_set_namespace(sock, if__ns)) != CONFD_OK)
return ret;
if ((proc = fopen("/proc/net/dev", "r")) == NULL)
return CONFD_ERR;
while (ret == CONFD_OK && fgets(buf, sizeof(buf), proc) != NULL) {
if ((p = strchr(buf, ':')) == NULL)
continue;
*p = ' ';
if ((ifname = strtok(buf, " \t")) == NULL)
continue;
i = 0;
CONFD_SET_XMLTAG(&val[i], if_receive, if__ns); i++;
GET_COUNTER(); /* rx bytes */
CONFD_SET_UINT64(&val[i], counter); i++;
GET_COUNTER(); /* rx packets */
CONFD_SET_UINT64(&val[i], counter); i++;
GET_COUNTER(); /* rx errs */
CONFD_SET_UINT32(&val[i], counter); i++;
GET_COUNTER(); /* rx drop */
CONFD_SET_UINT32(&val[i], counter); i++;
/* skip remaining rx counters */
GET_COUNTER(); GET_COUNTER(); GET_COUNTER(); GET_COUNTER();
CONFD_SET_XMLTAG(&val[i], if_transmit, if__ns); i++;
GET_COUNTER(); /* tx bytes */
CONFD_SET_UINT64(&val[i], counter); i++;
GET_COUNTER(); /* tx packets */
CONFD_SET_UINT64(&val[i], counter); i++;
GET_COUNTER(); /* tx errs */
CONFD_SET_UINT32(&val[i], counter); i++;
GET_COUNTER(); /* tx drop */
CONFD_SET_UINT32(&val[i], counter); i++;
GET_COUNTER(); /* skip */
GET_COUNTER(); /* tx colls */
CONFD_SET_UINT32(&val[i], counter); i++;
ret = cdb_set_object(sock, val, i,
"/interfaces/interface{%s}/status", ifname);
if (ret == CONFD_ERR && confd_errno == CONFD_ERR_BADPATH)
/* assume interface doesn't exist in config */
ret = CONFD_OK;
}
fclose(proc);
cdb_end_session(sock);
return ret;
}
We typically call this function at regular intervals.
If the data source is communicated with through some means of IPC it may be inconvenient to hang in the callback functions and wait for the reply from the data source. The solution to this problem is to return a special return value from the callback and then later explicitly send the response once it is available.
All the transaction callbacks as well as all the data callbacks
can optionally return the value CONFD_DELAYED_RESPONSE.
This means that the callback returns, and we typically end up in
our main poll loop again. Once the reply returns it is then up
to the application to send the reply back to ConfD.
The libconfd library contains a number of routines
that can be invoked to convey a delayed response. The callbacks
are divided in two groups. The first group is the one where
the actual return value from the callback is the value that
is sent to ConfD as a response. A good example is the
the transaction init() callback or the the data callback
set_elem(). In both these case if the callback returns
CONFD_OK a positive ack is sent back to ConfD by the
library. If we instead return CONFD_DELAYED_RESPONSE
the application must - once the reply is available - use either
of the functions confd_delayed_reply_ok() or
confd_delayed_reply_error() to explicitly send the
reply. If no reply is sent within 120 seconds (configurable through
confd.conf) the data provider is considered dead by
ConfD and ConfD will close all sockets to the data provider.
Another group of callbacks are the callbacks that require the
application to explicitly send a reply back to ConfD before
returning. A good example is the data callback
get_elem(). The application must
explicitly call confd_data_reply_value()
before returning - unless the
CONFD_DELAYED_RESPONSE value is
returned. If so, it is up to the application to later, when
the response value is available, explicitly call the
confd_data_reply_value() function to send
back the return value.
For operational data handled by an external data provider (i.e.,
using tailf:callpoint), the values of elements may be kept
for a certain time in a cache in ConfD. If such an element is
accessed, its value will be taken from the cache, and the data
provider not called.
The cache is enabled, and the default time to keep values in
the cache configured, with the element
/confdConfig/opcache in the
confd.conf file, for example:
<opcache>
<enabled>true</enabled>
<timeout>5</timeout>
</opcache>By default, the cache is disabled. The timeout value is given in seconds, it does not have a default. If confd --reload is done, the cache will use the new timeout value. If the cache is disabled, the stored values are cleared.
To indicate that the elements handled by a callpoint are to be
saved in the cache, use the tailf:cache statement:
leaf packetCounter {
type uint64;
config false;
tailf:callpoint a1 {
tailf:cache true;
}
}
It is also possible to override the cache timeout specified in
confd.conf by using the
tailf:timeout substatement with
tailf:cache in the data model.
leaf packetCounter {
type uint64;
config false;
tailf:callpoint a1 {
tailf:cache true {
tailf:timeout 7;
}
}
}
The timeout specified this way will be used for the node with
the tailf:timeout statement and any descendants
of that node, unless another tailf:cache
statement is used on a descendant node. Using
tailf:cache without a tailf:timeout
substatement will cause the timeout to revert to the one
specified in confd.conf.
The results of get_next() and
find_next() operations can not be cached in
general, since the next value returned
by the data provider does not necessarily identify a specific
list entry (e.g. it could be a fixed pointer to a data
structure holding the "next entry" information). However in
the special case that the data provider returns
-1 for next the
result can be cached, since retrieval of the next entry will
then use a find_next operation with the complete
set of keys from the previous entry. See the confd_lib_dp(3) manual page for further
details.
The cache can be cleared, partially or completely, by means of
the maapi_clear_opcache() function - see
the confd_lib_maapi(3) manual page.
It is possible to define lists for operational data without any keys in the YANG data model, e.g.:
list memory-pool {
config false;
tailf:callpoint memstats;
leaf buffer-size {
type uint32;
}
leaf number-of-buffers {
type uint32;
}
}To support this without having completely separate APIs, we
use a "pseudo" key in the ConfD APIs for this type of list. This
key is not part of the data model, and completely hidden in the
northbound agent interfaces, but is used with e.g. the
get_next() and
get_elem() callbacks as if it were a normal
key.
This "pseudo" key is always a single signed 64-bit integer,
i.e. the confd_value_t type is
C_INT64. The values can be chosen arbitrarily
by the application, as long as a key value returned by
get_next() can be used to get the data for
the corresponding list entry with get_elem()
or get_object() as usual. It could e.g. be an
index into an array that holds the data, or even a memory address
in integer form.
There are some issues that need to be considered though:
In some cases ConfD will do an "existence test" for a list entry. For "normal" lists, this is done by requesting the first key leaf via
get_elem(), but since there are no key leafs, this can not be done. Instead ConfD will use theexists_optional()callback for this test. I.e. a data provider that has this type of list must implement this callback, and handle a request where the keypath identifies a list entry.In the response to the
get_next_object()callback, the data provider is expected to provide the key values along with the other leafs in an array that is populated according to the data model. This must be done also for this type of list, even though the key isn't actually in the data model. The "pseudo" key must always be the first element in the array, and for theconfd_data_reply_next_object_tag_value_array()reply function, the tag value 0 should be used. Note that the key should not be included in the response to theget_object()callback.The same approach is used when we store operational data in CDB - the path used in the write (and read) functions in the CDB API must include the "pseudo" integer key. If multiple list entries are to be written with a single call to
cdb_set_values(), which takes a tagged value array, the key for each entry must be included in the array with a tag value of 0, in the same way as described above. This applies also to reading multiple entries with a single call tocdb_get_values().